Kontatto. Nasce il primo corpus di parlato autentico sudtirolese

Dal dizionario del dialetto della Val Passiria compilato dal linguista meranese Franz Lanthaler al riconoscimento vocale del sudtirolese con Siri, il passo è tutt’altro che breve. Li separano, più o meno, 150.000 parole e anni di ricerca. Ma il cammino ora è aperto, grazie alla creazione del primo corpus di parlato autentico bilingue. Il team di studiosi guidato da Silvia Dal Negro lo ha reso accessibile alla comunità scientifica internazionale.
Tutto nasce dal progetto di ricerca “Kontatto. Italiano-Tedesco: aree storiche di contatto tra Sudtirolo e Trentino” che, tra il 2011 e il 2014, ha indagato la reciproca influenza tra italiano e tedesco nella Bassa Atesina. Un ramo di quel progetto prevedeva la registrazione di parlato autentico bilingue. E quale zona più adatta a raccogliere materiale del territorio tra Salorno e Bolzano, in cui da secoli, diversi sistemi linguistici si intrecciano?
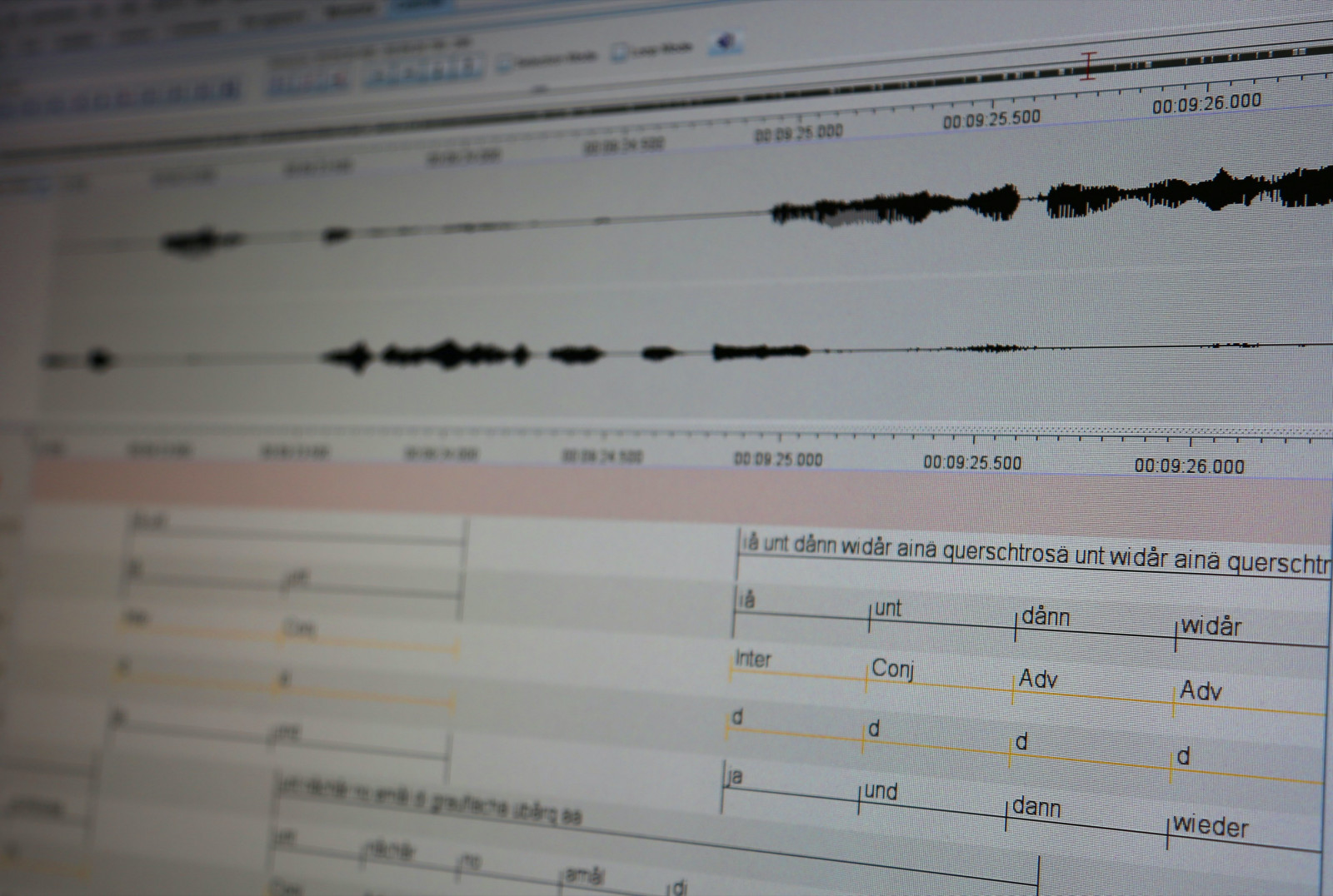
“Uno dei nostri scopi era capire come i parlanti bilingui parlano nell’interazione quotidiana per poi dar vita a un modello che, fra le altre cose, possa orientare chi vuole imparare la lingua”, spiega Silvia Dal Negro, coordinatrice di “Kontatto” e professoressa di Linguistica alla Facoltà di Scienze della Formazione di Bressanone. Per centrare l’obiettivo, il team di ricerca guidato da Dal Negro, che comprende i ricercatori Simone Ciccolone e Marta Ghilardi – e, prima di loro, le ricercatrici sudtirolesi Mara Leonardi e Katrin Tartarotti - ha ascoltato, frammentato, categorizzato, 18 ore di registrazioni di conversazione di una novantina di giovani parlanti bilingui di età tra i 20 e i 30 anni. La maggioranza delle registrazioni è stata effettuata all’interno di discussioni di gruppi di amici: al bar, in paese, in varie situazioni della vita di tutti i giorni. Altre erano invece conversazioni orientate, in cui alle coppie era stato richiesto di rispondere, ad esempio, alla richiesta di indicazioni stradali per raggiungere una data località. Il sudtirolese registrato è stato trascritto basandosi sul “Passeirer Wörterbuch” di Franz Lanthaler risalente agli anni ’50 del Novecento.
Il corpus costruito dai ricercatori della Libera Università di Bolzano – denominato, come il progetto che l’ha generato, Kontatto - contiene circa 150.000 parole. È quindi di dimensioni modeste rispetto a giganti come il British National Corpus, composto da 100 milioni di parole. Ma è comunque un esperimento unico nel suo genere. In primo luogo perché è un corpus bilingue e poi perché raccoglie il parlato. Solitamente, i corpora contengono dati - parole e frasi - che sono stati tratti da testi scritti. “Avere a che fare con un testo scritto facilita la compilazione del database, dato che molte operazioni di riconoscimento possono essere automatizzate ed effettuate dal computer. Nel caso di un corpus di parlato, invece, ciò non è possibile”, spiegano Ciccolone e Ghilardi. In pratica, ciò significa che i linguisti di unibz hanno dovuto ascoltare le registrazioni, secondo dopo secondo. Solo così hanno potuto trascrivere tutte le parole del discorso e categorizzare ogni singolo elemento delle frasi.

La collaborazione con il Max Planck Institute
La lemmatizzazione degli elementi di pochi minuti di parlato si traduce in ore e ore di lavoro al computer. Ad assistere i ricercatori in questa fase, è venuto in soccorso un software all’avanguardia - Elan - messo a disposizione dal Max Planck Institute for Psycholinguistics di Nijmegen che permette di realizzare un database interrogabile dall’utente che può rintracciare i vari elementi – fonetici, sintattici, grammaticali - del parlato. Questo programma informatico garantisce inoltre la possibilità di rappresentare in forma grafica i dati ottenuti e vedere immediatamente, ad esempio, la distribuzione dei codici, ovvero quanti avverbi, quanti aggettivi e quanti sostantivi compongono il corpus. Ciò ha dimostrato che il dialetto sudtirolese parlato ha un comportamento simile a quello di altre lingue.
L’operazione che adesso stanno affrontando i ricercatori - sempre con l’aiuto di Elan - è la ricerca delle occorrenze, ovvero di quante volte si verifica un fenomeno, per poi trarne una regola. “Grazie al software possiamo effettuare una ricerca per consultare gli aggettivi, per esempio, gli avverbi o i sostantivi. Si possono trovare quali parole italiane seguono le tedesche e capire perché e quante volte succede”, spiegano i ricercatori di unibz. Elan, inoltre, permette di lavorare senza perdere di vista il parlato. Il dato audio può essere richiamato in qualsiasi momento chiarendo, per esempio, con quale intonazione viene pronunciata una data parola. “Normalmente, tendiamo a pensare che la lingua “giusta” sia quella scritta ma”, spiegano i tre linguisti, “dal punto di vista dell’apprendimento delle lingue, disporre di una fotografia o di un intero album fotografico, come in questo caso, ci permette di osservare come viene modellata la lingua nell’uso quotidiano”.
I possibili sviluppi del progetto
Adesso il Bozen-Bolzano Corpus - di cui il corpus Kontatto è parte, insieme ad altri raccolti negli anni presso il Centro di Competenza Lingue - sarà ospitato su una piattaforma del Max Planck Institute e dedicata ai linguisti. Questa sarà liberamente accessibile a chi, per ragioni professionali e di studio, ne farà richiesta. Ma il materiale costituisce una ricca base di partenza per confezionare una grammatica del sudtirolese e soddisfare, ad esempio, i desideri di chi voglia approfondire la lingua parlata dalla popolazione di madrelingua tedesca in Alto Adige.
“La collaborazione con il l’istituto di ricerca olandese ci assicura visibilità e circolazione del nostro studio nella comunità internazionale dei linguisti”, concludono Dal Negro e i suoi collaboratori, “ma adesso ci piacerebbe che servisse per creare strumenti per la didattica e, ad esempio, a eventuali sviluppi legati a tecnologie come il riconoscimento vocale. Al momento non è possibile parlare in sudtirolese con Siri o Google Now. Ci piace pensare che uno dei possibili esiti della nostra ricerca sia la compatibilità di questi nuovi strumenti anche con le lingue meno diffuse”.
Related Articles
Tecno-prodotti. Creati nuovi sensori triboelettrici nel laboratorio di sensoristica al NOI Techpark
I wearable sono dispositivi ormai imprescindibili nel settore sanitario e sportivo: un mercato in crescita a livello globale che ha bisogno di fonti di energia alternative e sensori affidabili, economici e sostenibili. Il laboratorio Sensing Technologies Lab della Libera Università di Bolzano (unibz) al Parco Tecnologico NOI Techpark ha realizzato un prototipo di dispositivo indossabile autoalimentato che soddisfa tutti questi requisiti. Un progetto nato grazie alla collaborazione con il Center for Sensing Solutions di Eurac Research e l’Advanced Technology Institute dell’Università del Surrey.

unibz forscht an technologischen Lösungen zur Erhaltung des Permafrostes in den Dolomiten
Wie kann brüchig gewordener Boden in den Dolomiten gekühlt und damit gesichert werden? Am Samstag, den 9. September fand in Cortina d'Ampezzo an der Bergstation der Sesselbahn Pian Ra Valles Bus Tofana die Präsentation des Projekts „Rescue Permafrost " statt. Ein Projekt, das in Zusammenarbeit mit Fachleuten für nachhaltiges Design, darunter einem Forschungsteam für Umweltphysik der unibz, entwickelt wurde. Das gemeinsame Ziel: das gefährliche Auftauen des Permafrosts zu verhindern, ein Phänomen, das aufgrund des globalen Klimawandels immer öfter auftritt. Die Freie Universität Bozen hat nun im Rahmen des Forschungsprojekts eine erste dynamische Analyse der Auswirkungen einer technologischen Lösung zur Kühlung der Bodentemperatur durchgeführt.

Gesunde Böden dank Partizipation der Bevölkerung: unibz koordiniert Citizen-Science-Projekt ECHO
Die Citizen-Science-Initiative „ECHO - Engaging Citizens in soil science: the road to Healthier Soils" zielt darauf ab, das Wissen und das Bewusstsein der EU-Bürger:innen für die Bodengesundheit über deren aktive Einbeziehung in das Projekt zu verbessern. Mit 16 Teilnehmern aus ganz Europa - 10 führenden Universitäten und Forschungszentren, 4 KMU und 2 Stiftungen - wird ECHO 16.500 Standorte in verschiedenen klimatischen und biogeografischen Regionen bewerten, um seine ehrgeizigen Ziele zu erreichen.

Erstversorgung: Drohnen machen den Unterschied
Die Ergebnisse einer Studie von Eurac Research und der Bergrettung Südtirol liegen vor.